video
data
writing
More
POLITICO
5 charts show China’s oil dilemma after US strikes
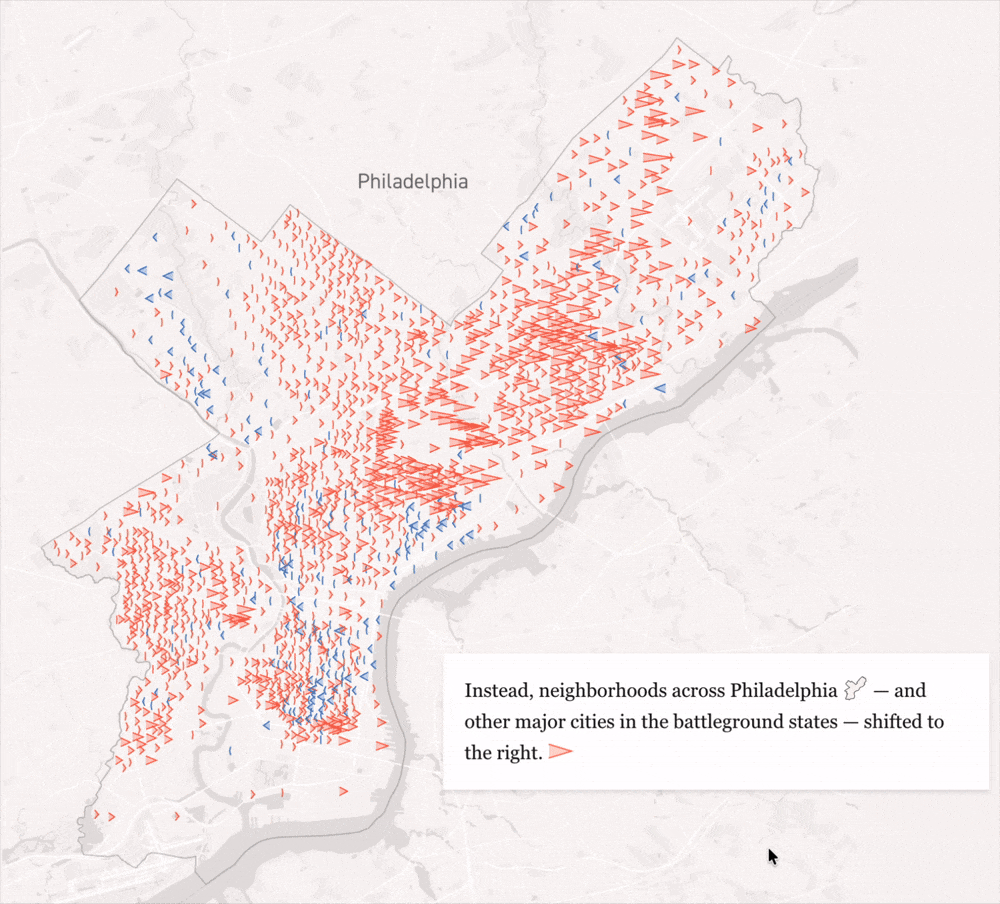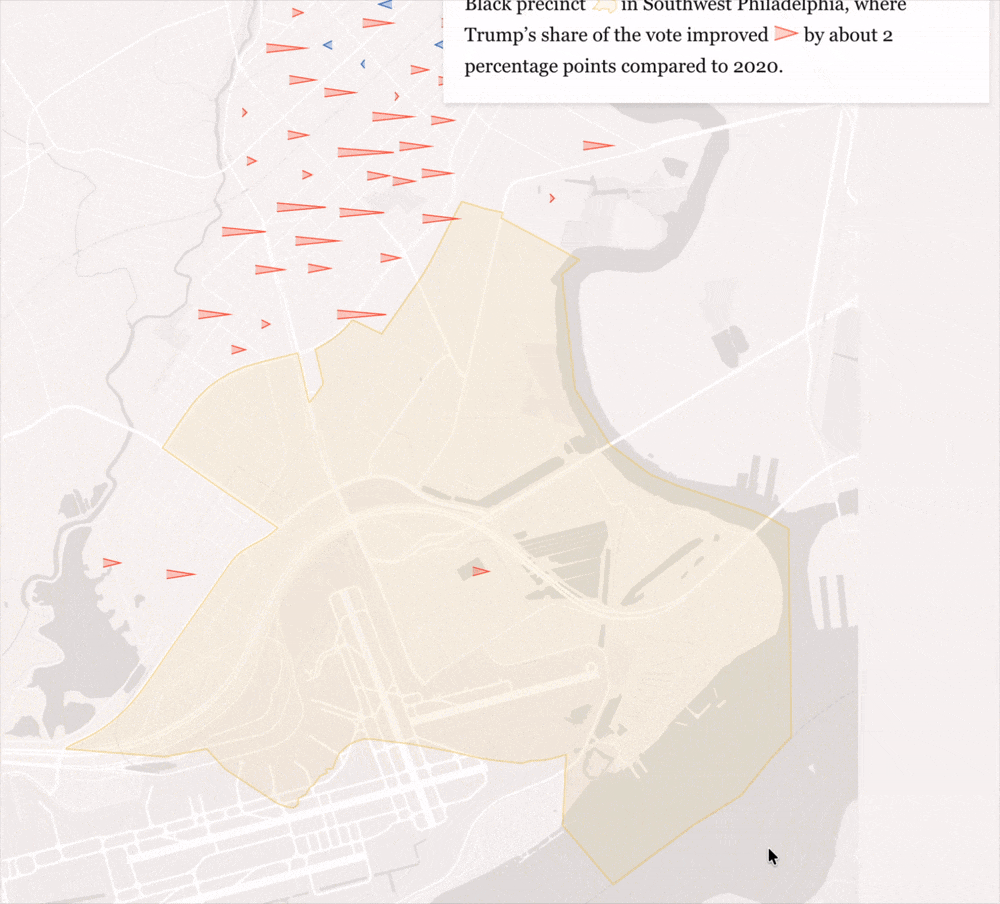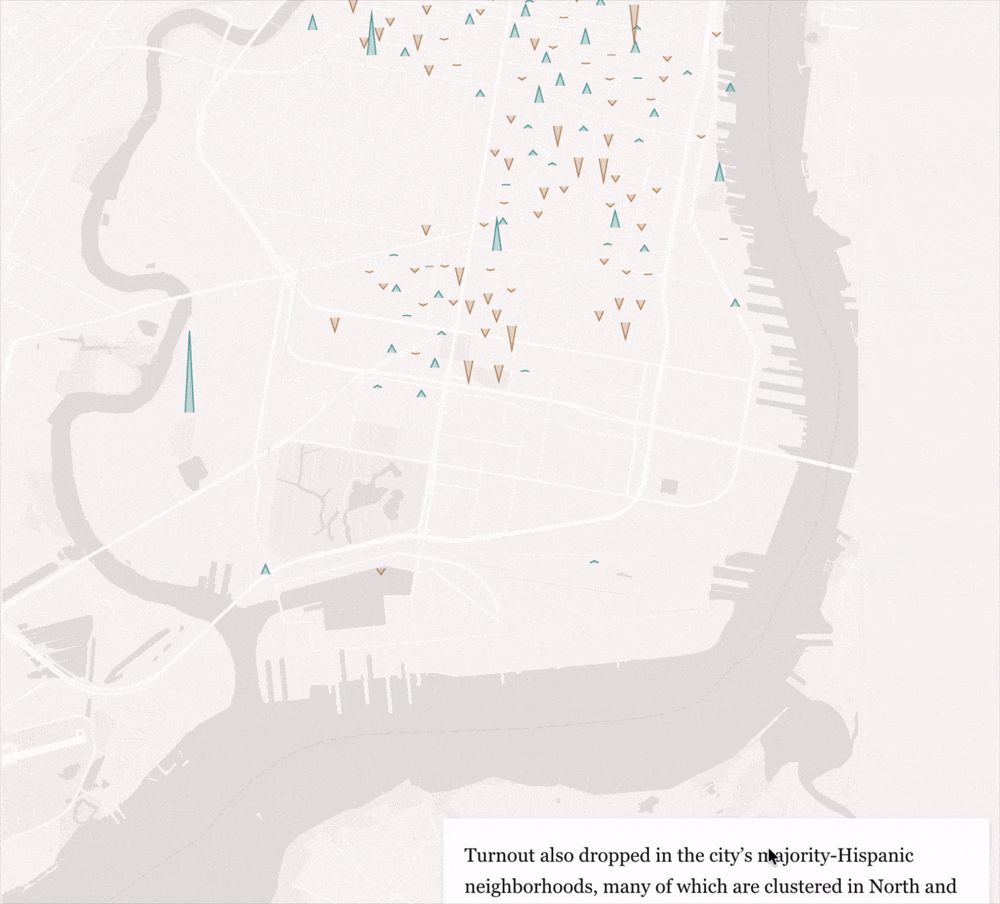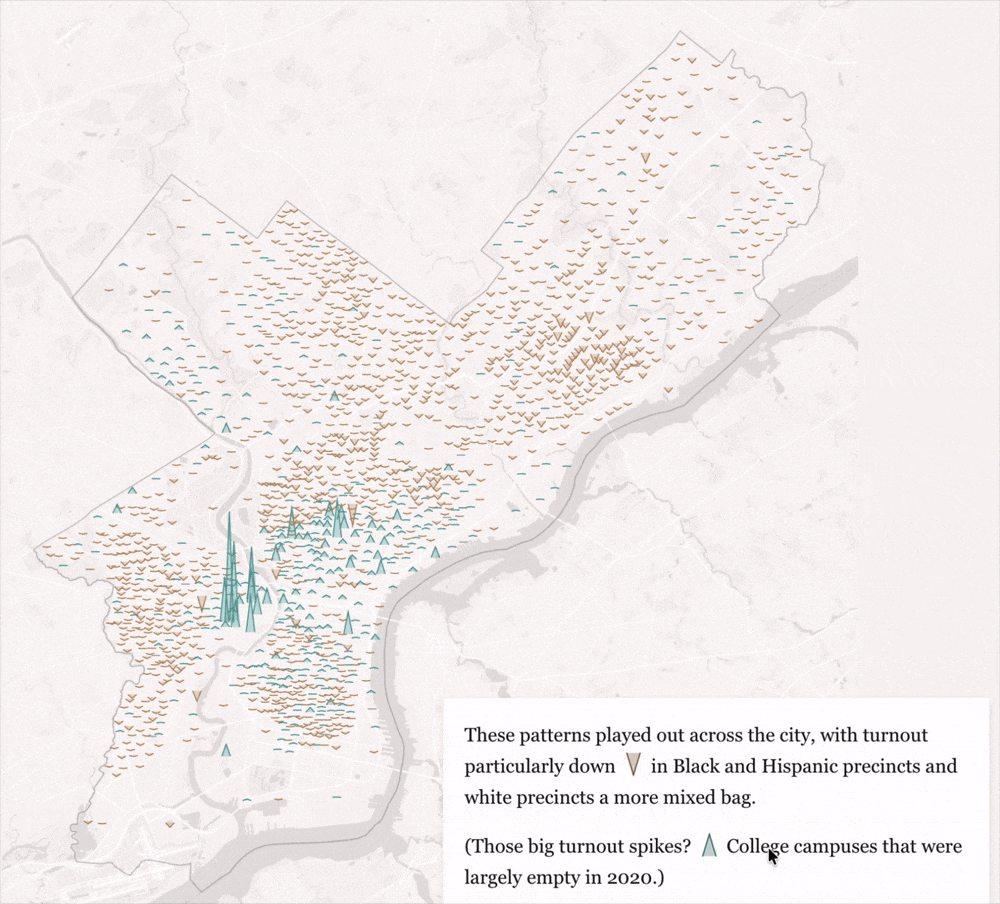
How Kamala Harris lost voters in the battlegrounds’ biggest cities
Mike Johnson’s Florida SNAP problem
FIVETHIRTYEIGHT
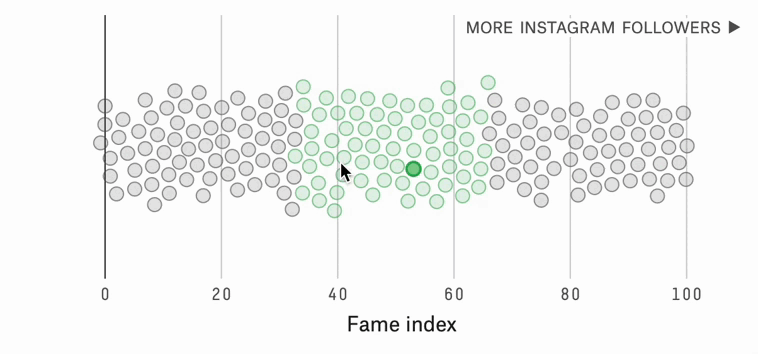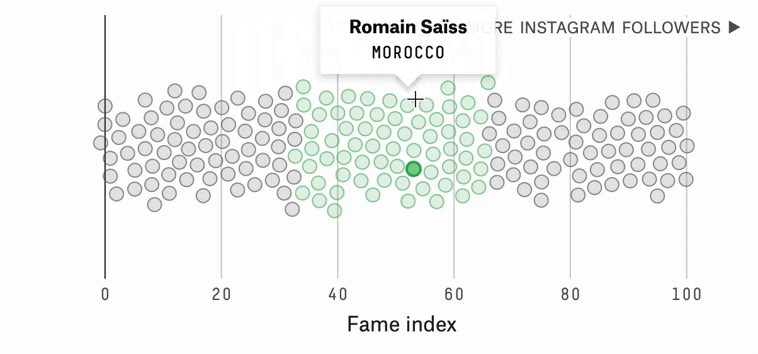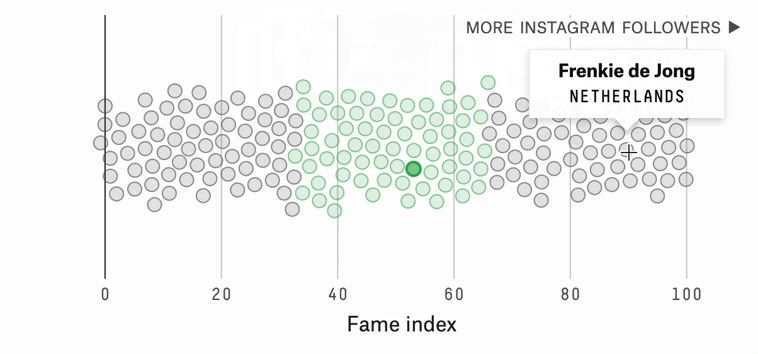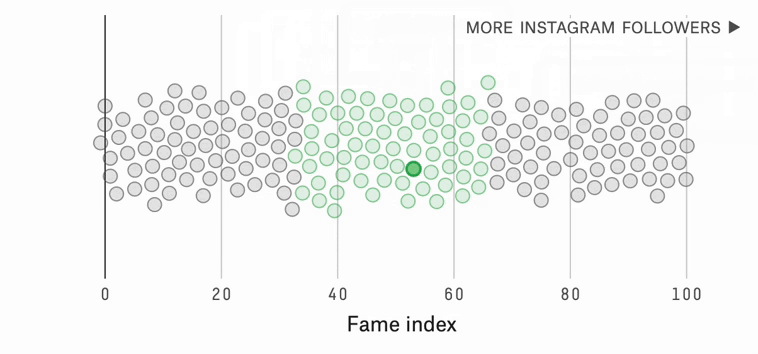
Which World Cup Player Should You Root For?
COLUMBIA JOURNALISM REVIEW
Online censorship is growing in Modi's India
-
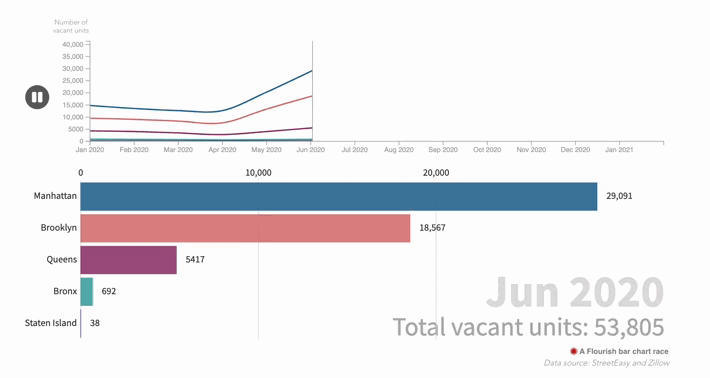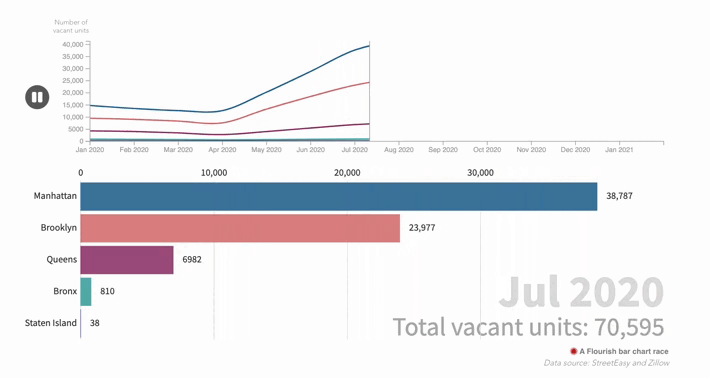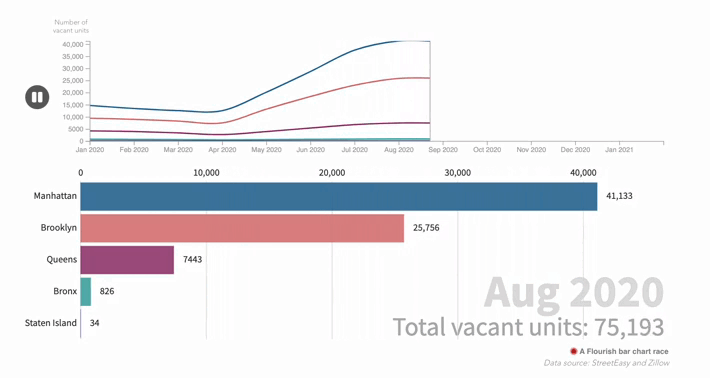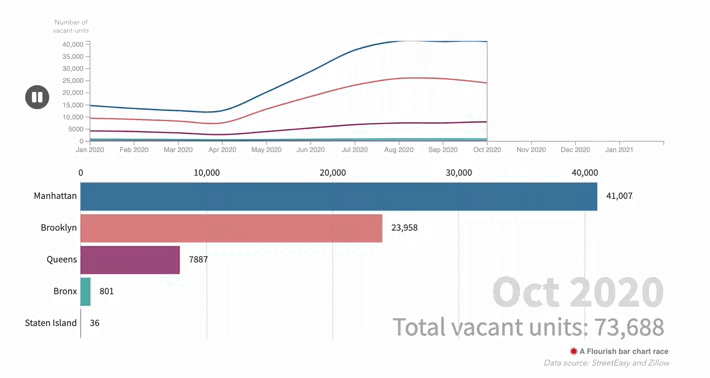
The cost of living in a 'ghost town': how the pandemic changed New York's real estate
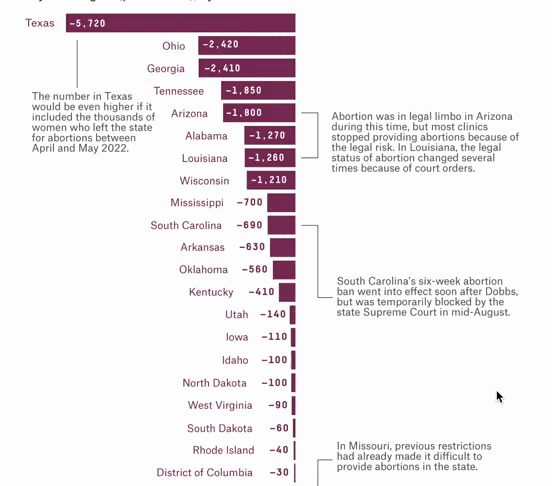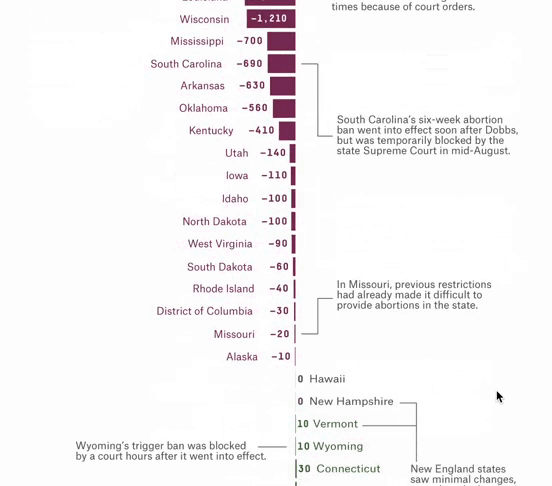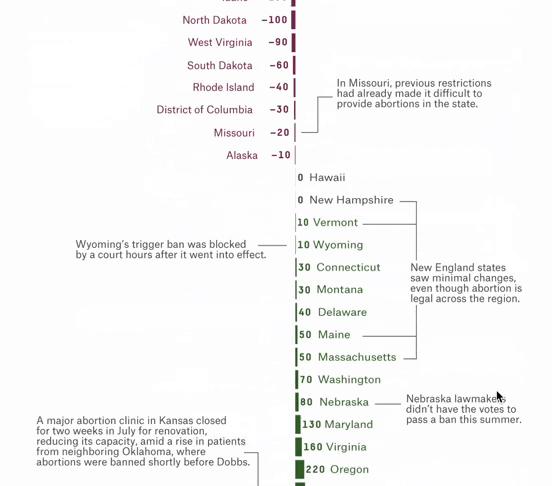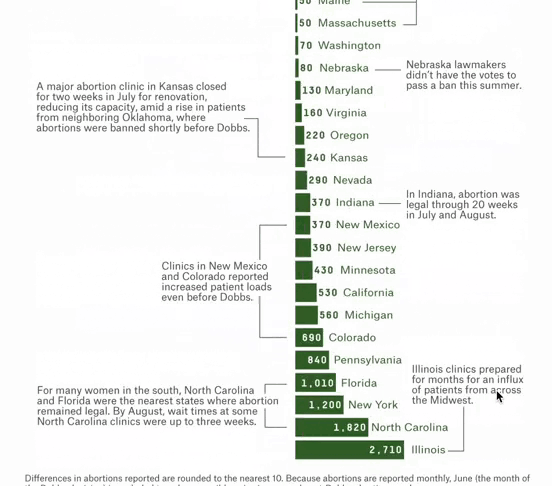
Overturning Roe Has Meant At Least 10,000 Fewer Legal Abortions
The 4 Political Neighborhoods Of Chicago
NY CITY LENS
A City Awash in Cherry Blossoms
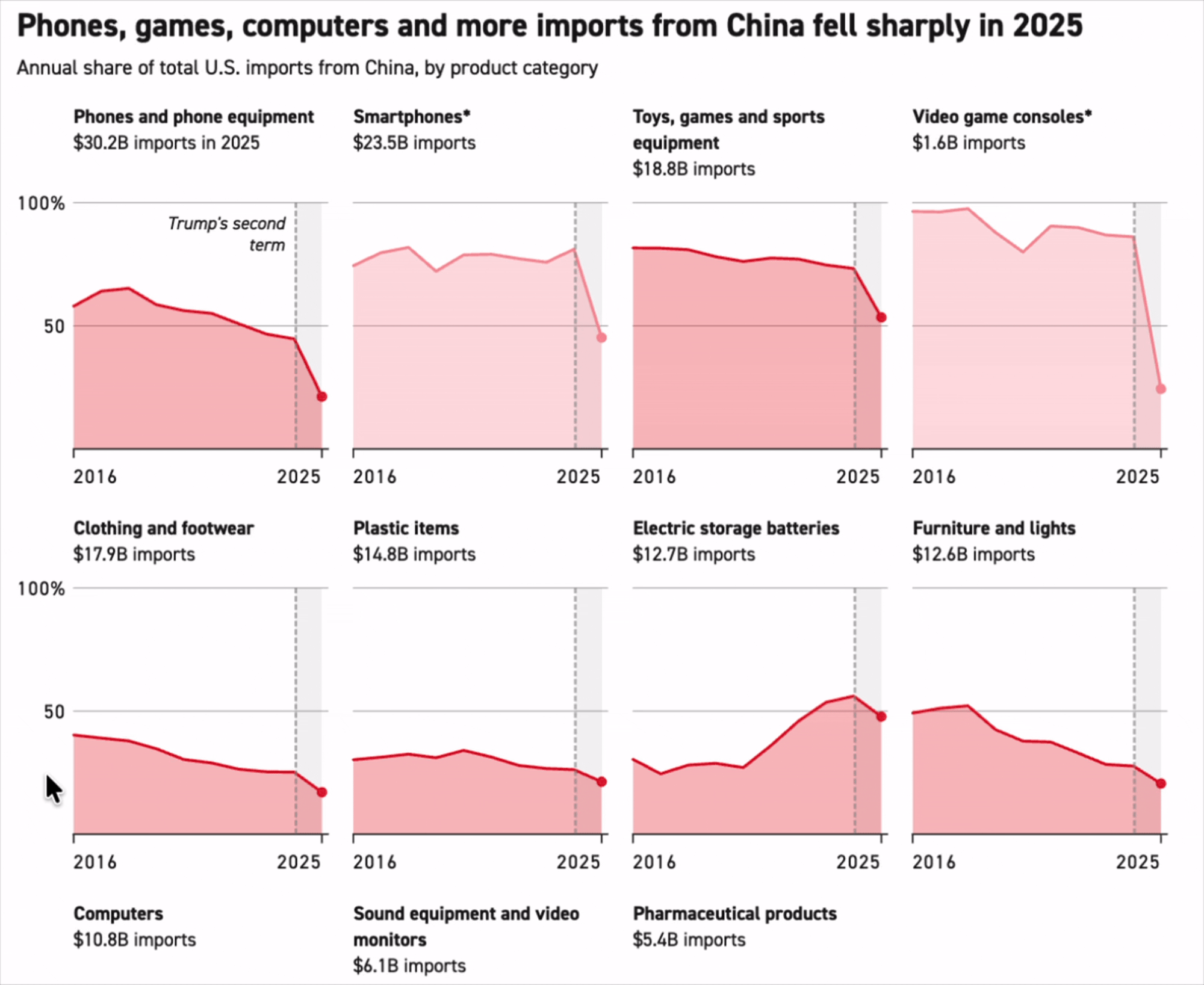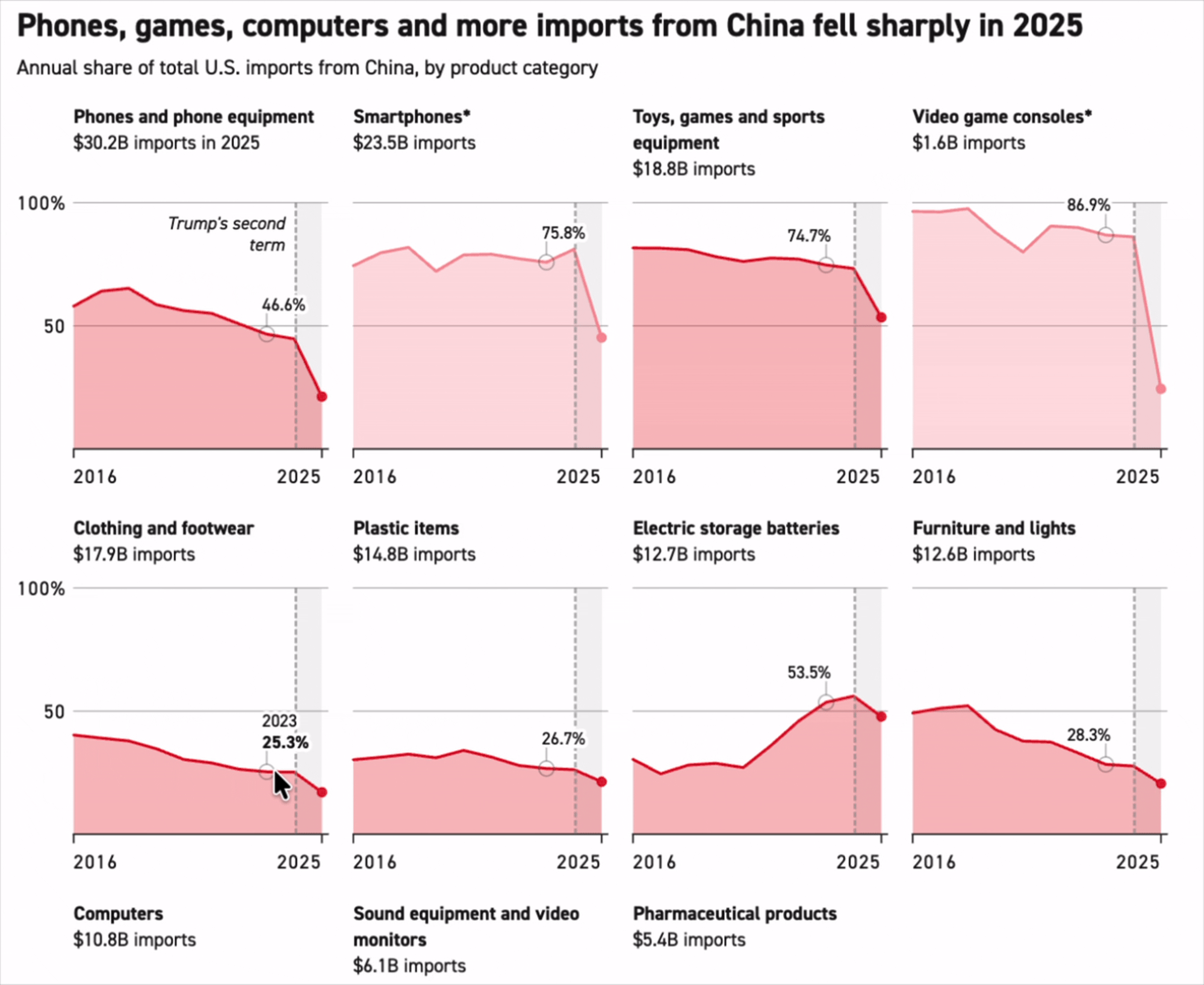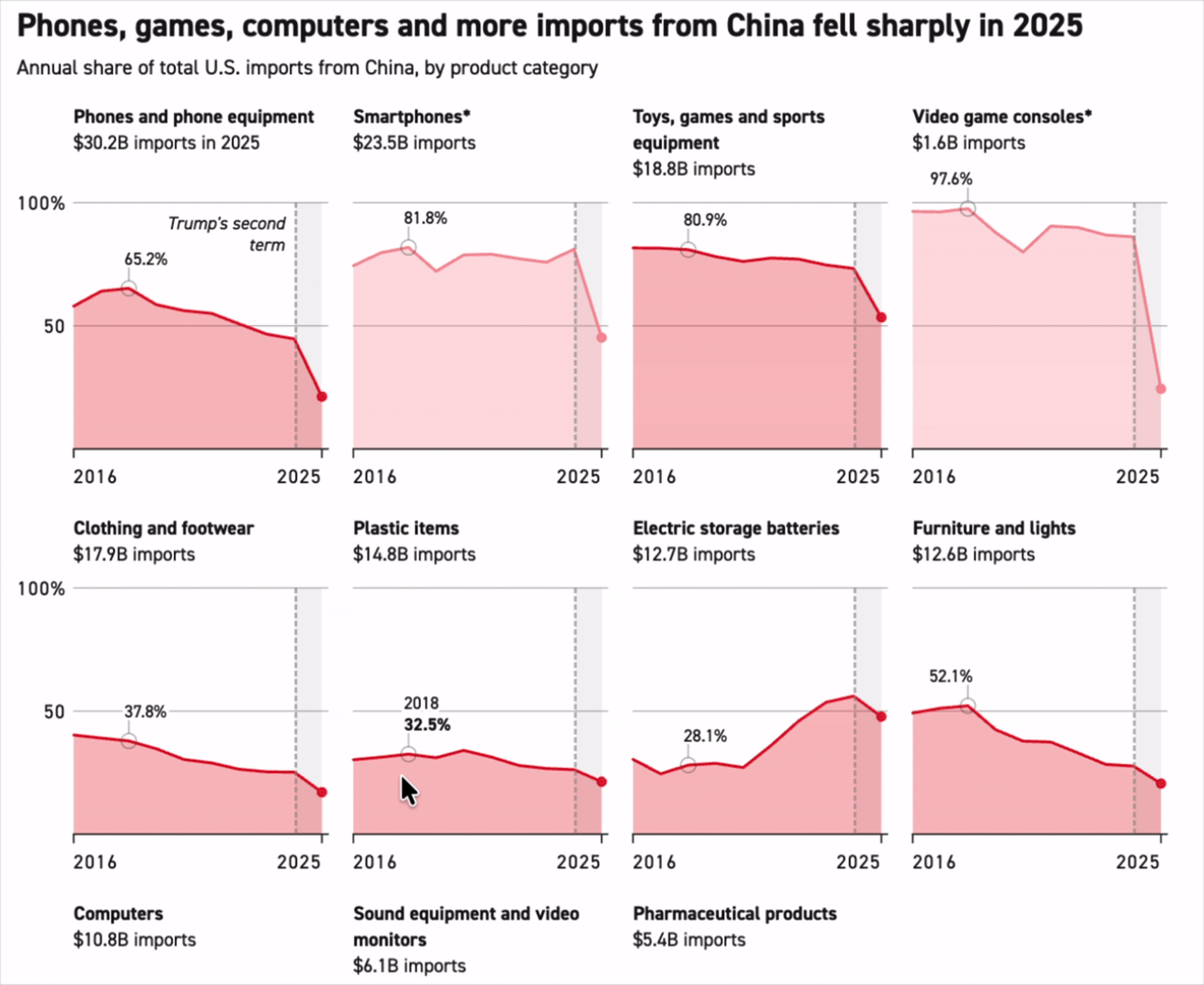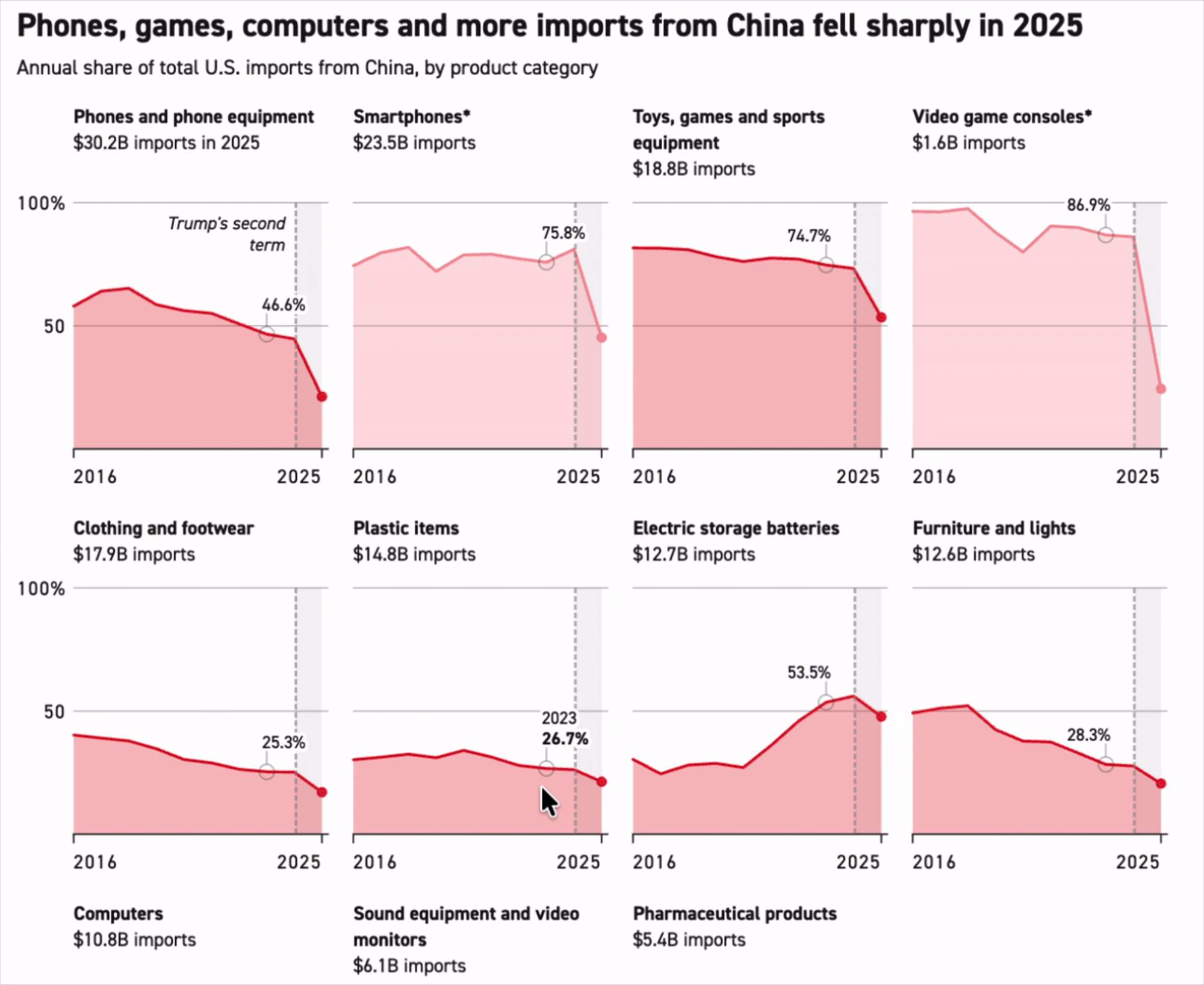
'China is falling across the board’: How the US is moving away from Chinese imports
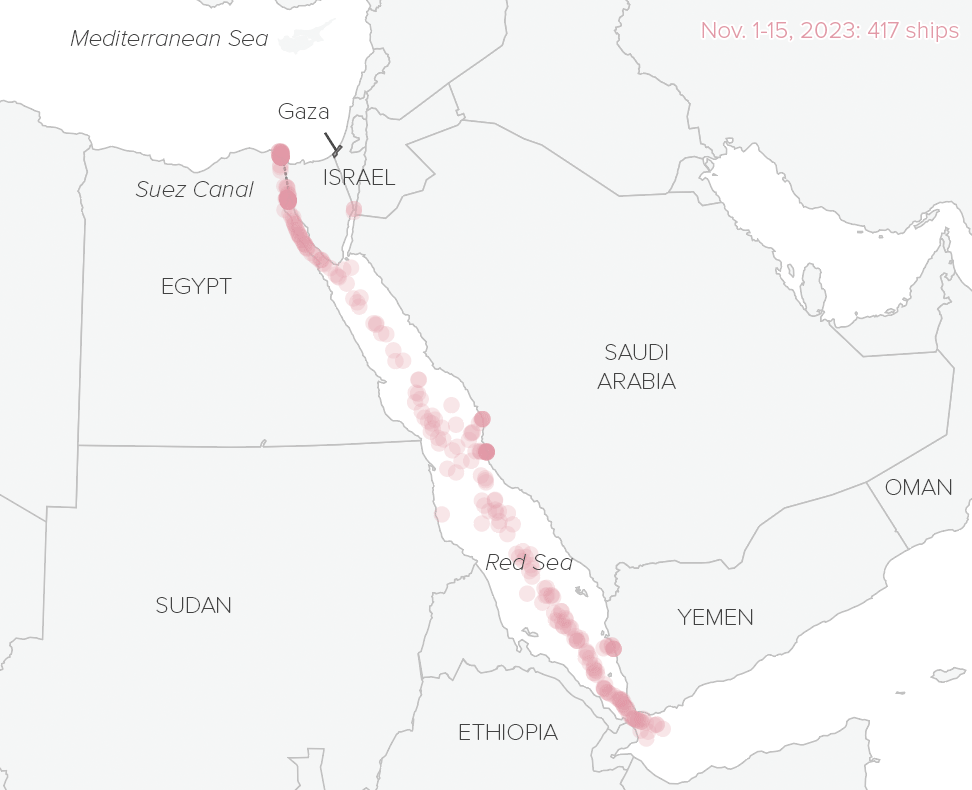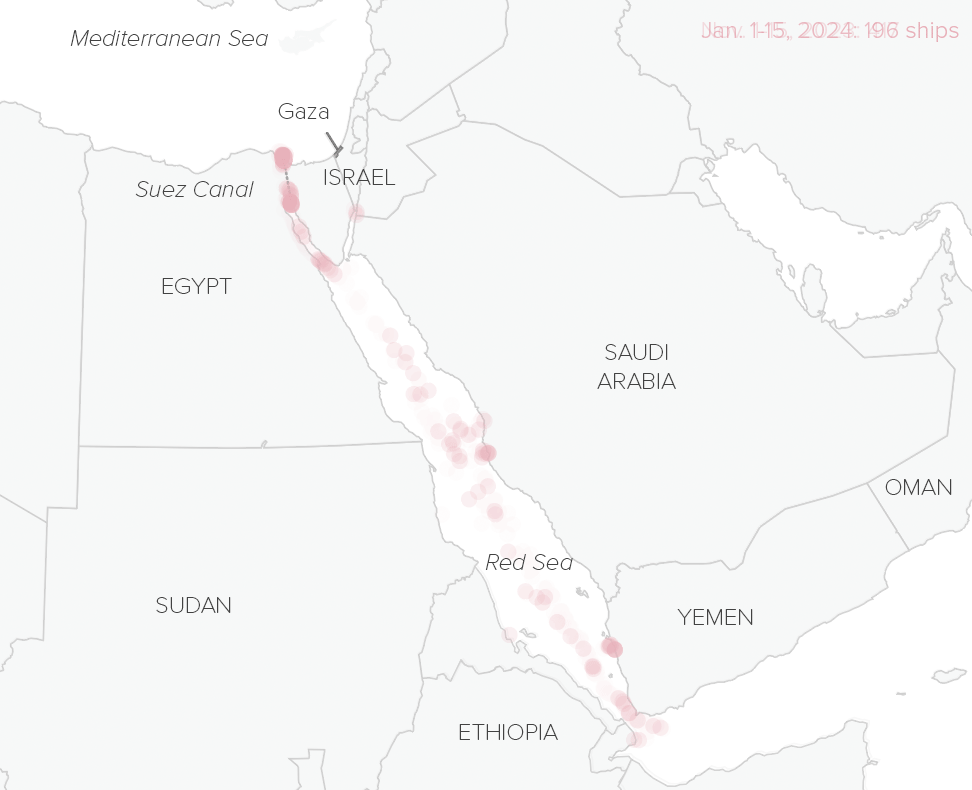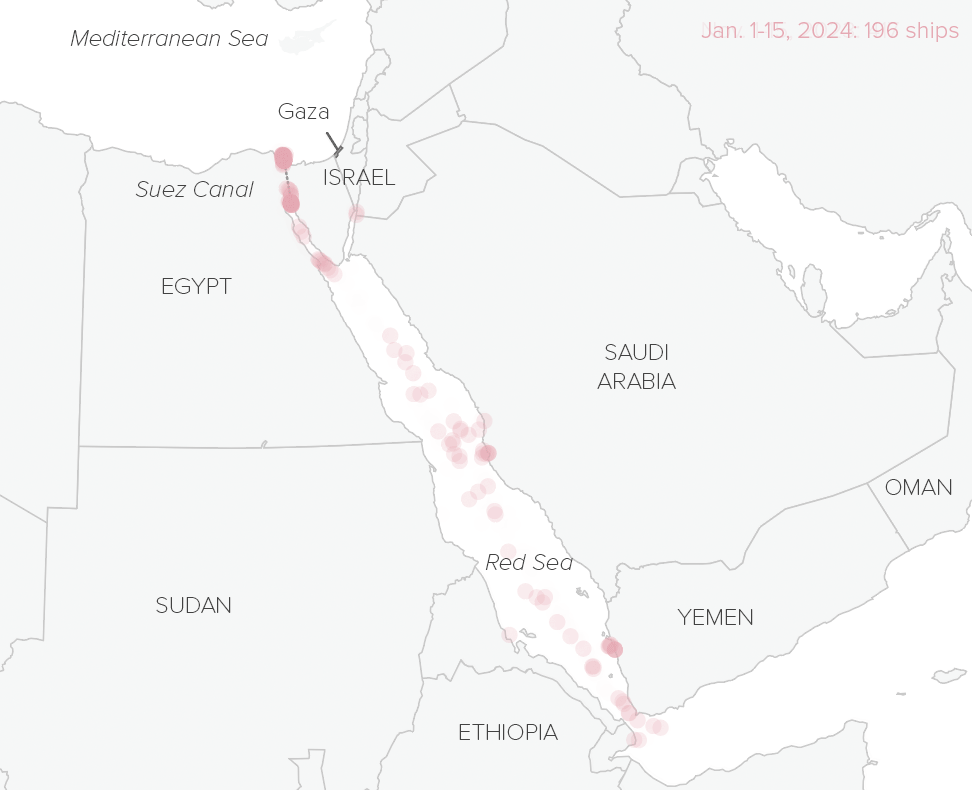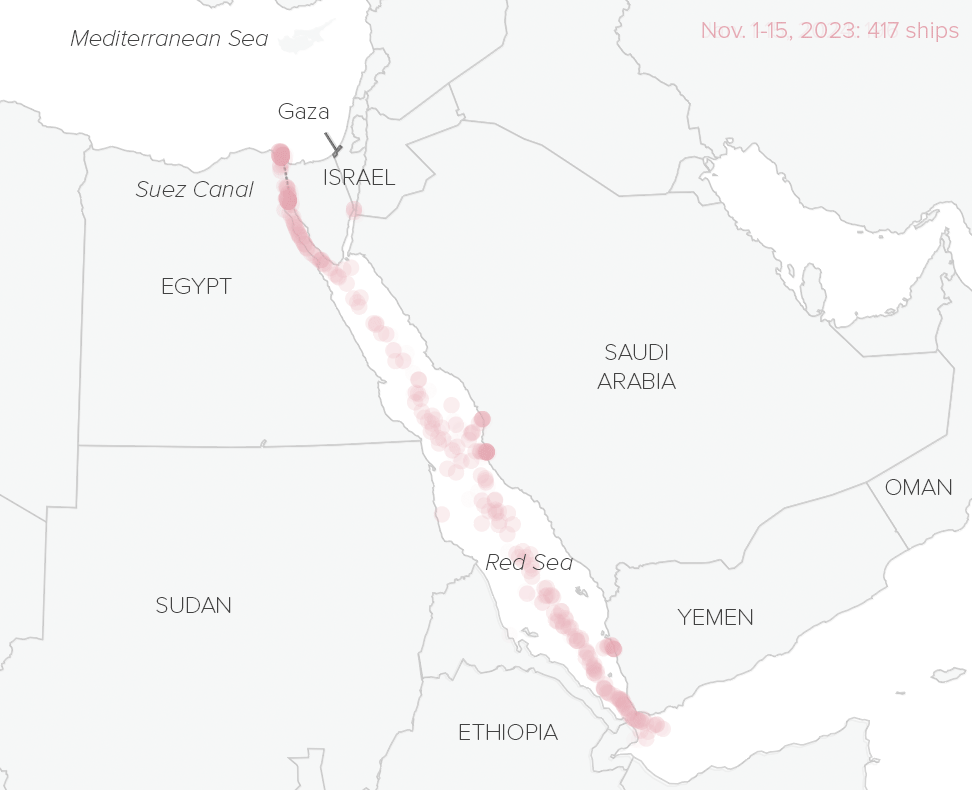
How conflict in the Red Sea disrupts global trade
60 Percent Of Americans Will Have An Election Denier On The Ballot This Fall
Over 66,000 People Couldn’t Get An Abortion In Their Home State After Dobbs
A pandemic of gun violence in New York City
The mystery of New York City's public assistance denials
Are Blue States Ready To Relax Their Bans On Later Abortions?
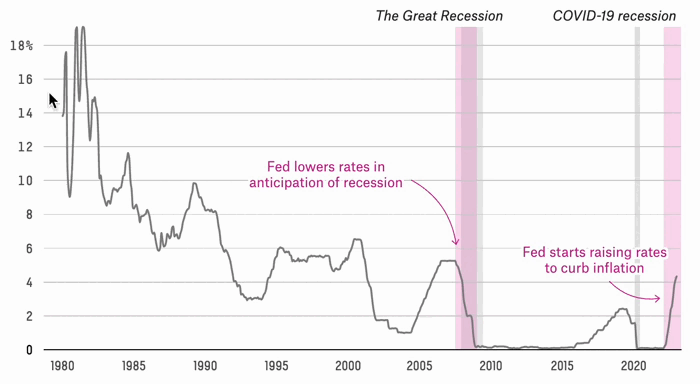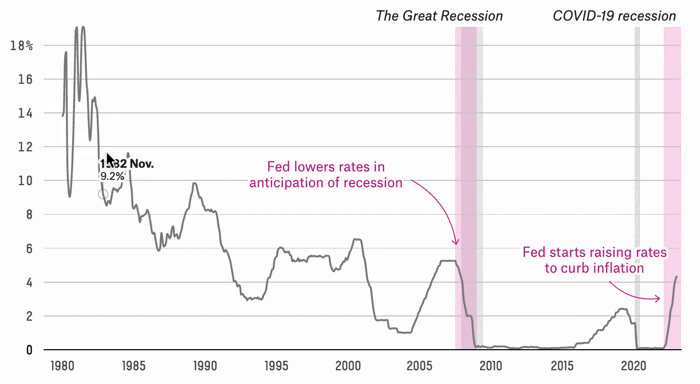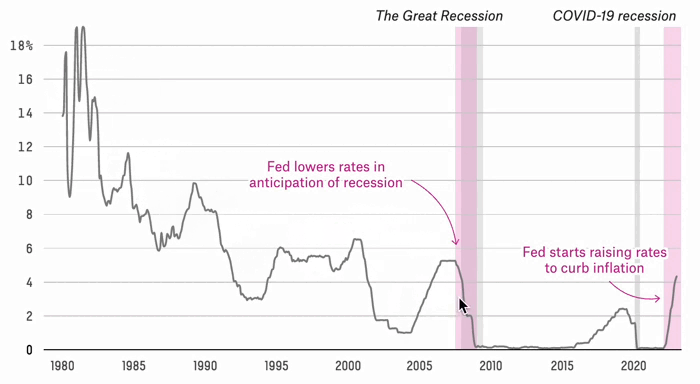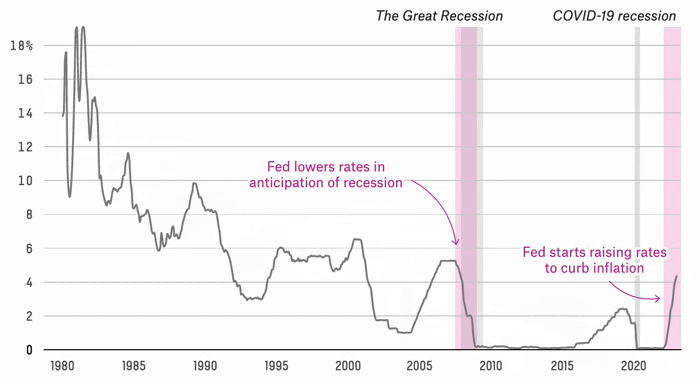
Are We Headed For A Recession Or Not?
Thousands of carve-outs and caveats are weakening Trump’s emergency tariffs
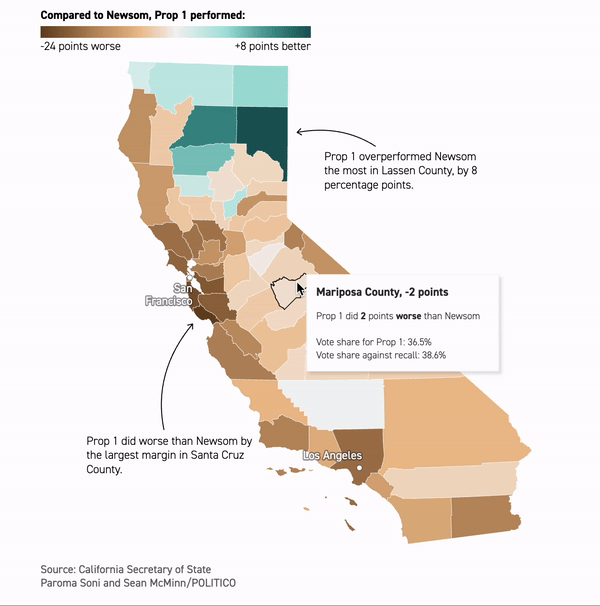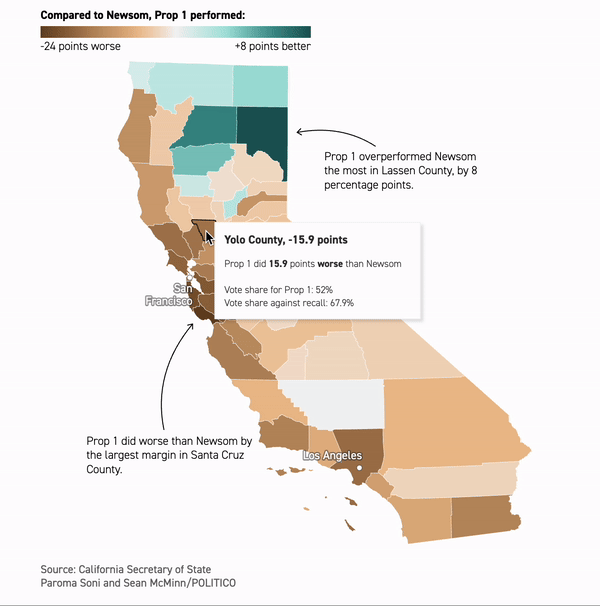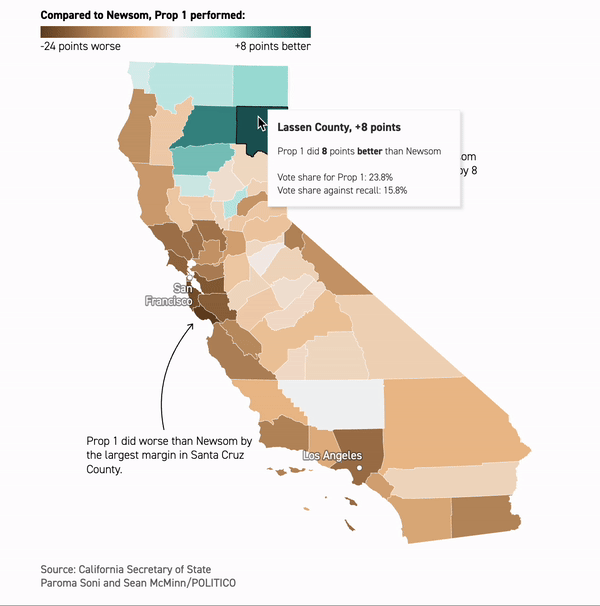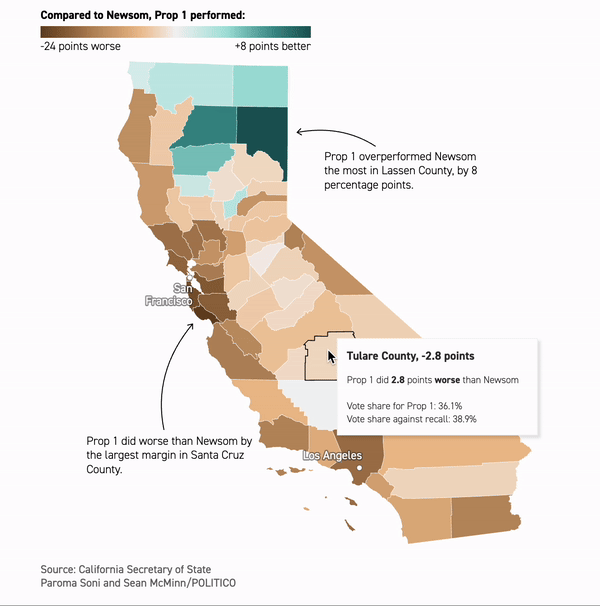
Inside Gavin Newsom’s brush with failure
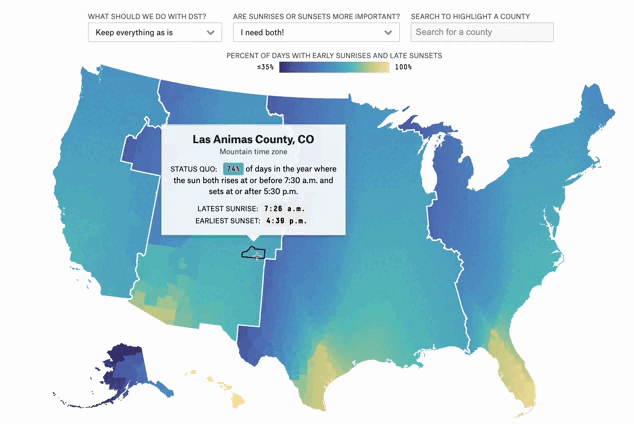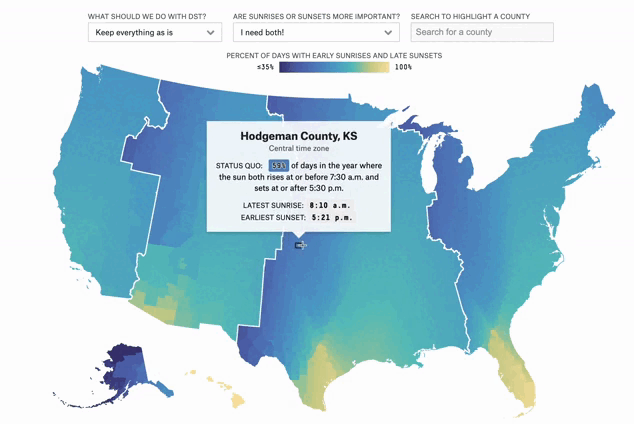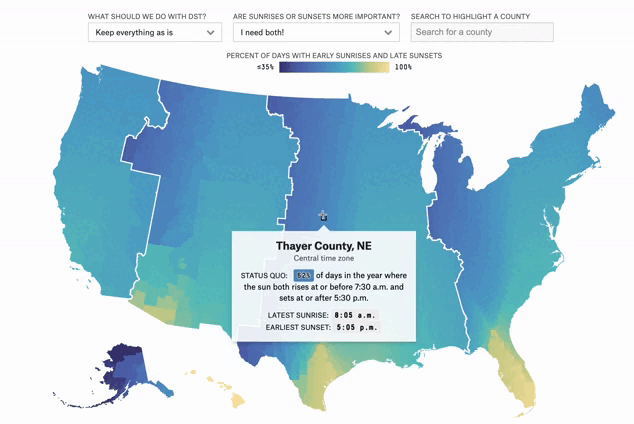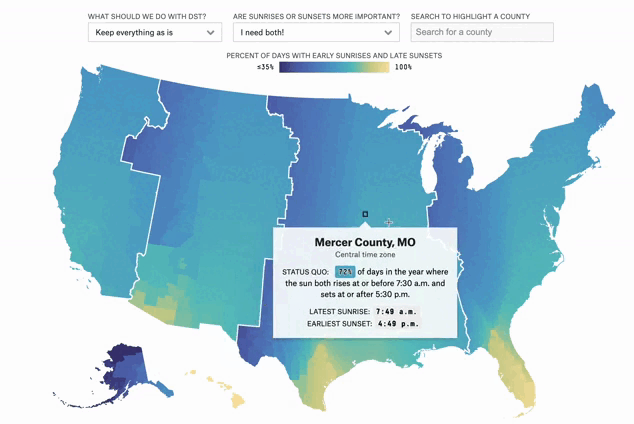
Can You Make Winter Less Dark?
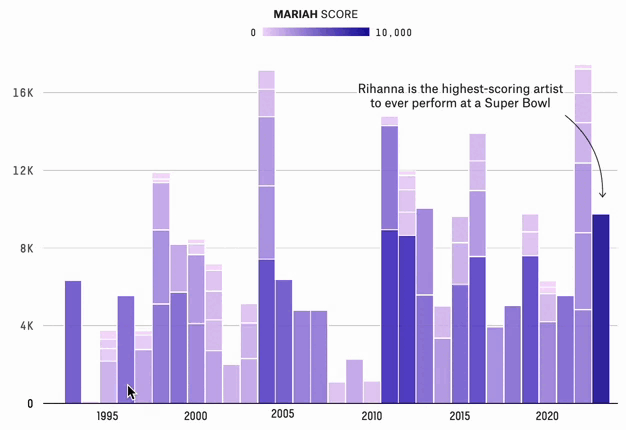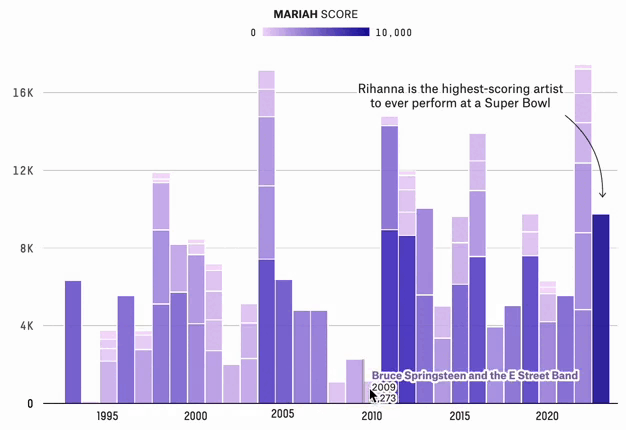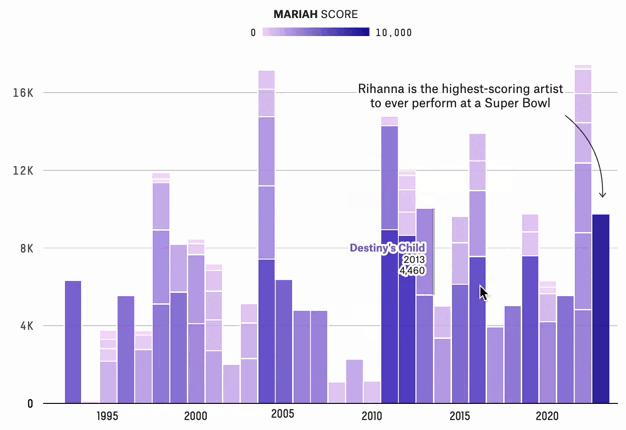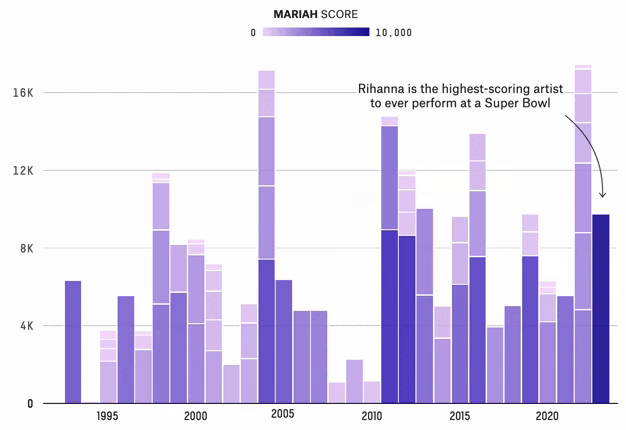
The Super Bowl Halftime Shows With The Most Star Power
Empty and Decaying: Climate and economic migration leaves thousands of houses abandoned in Puerto Rico
Can Democrats Win 52 Senate Seats And Kill The Filibuster?
Want To Know Where The Supreme Court Goes Next? Look At Alito's And Thomas's Dissents.
Rents Are Still Higher Than Before The Pandemic — And Assistance Programs Are Drying Up